Important and recurring phrases in neural networks and what do they mean
In previous and future posts I am referring to different terms from the AI and deep learning world (Encoding-decoding in https://2d3d.ai/index.php/2019/10/11/implicit-decoder-part-1-3d-reconstruction/ ), in this post we will explain their meaning. This post will be updated constantly to account for more terms that might not be written or new terms that become standard in the industry.
What is encoder-decoder?
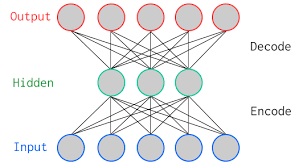
- Encoder – Maps input data (features) into a different representation. Usually the representation is in a lower space, allowing both for compression of the input data and more efficient representation of the important parts of the input.
- Decoder – Maps encoded data into output data. The decoder is trained to understand the underlying representation of the original pre-encoded input data based on the encoded features and can produce output based on this underlying representation.
What is autoencoder?
An autoencoder is a type of encoder-decoder network where the decoder outputs the encoded data back to its’ original input structure. Why is it an interesting type of network?
- It allows for compression of data (for example, images) and then reconstructing back the original data with low data loss.
- Training and autoencoder is a good method to train an encoder network to be a dimensionality reduction tools (much like PCA) which can represent the input data in a lower dimension vector, keeping the information about the important parts of the data.
What is RNN (recurrent neural network)?
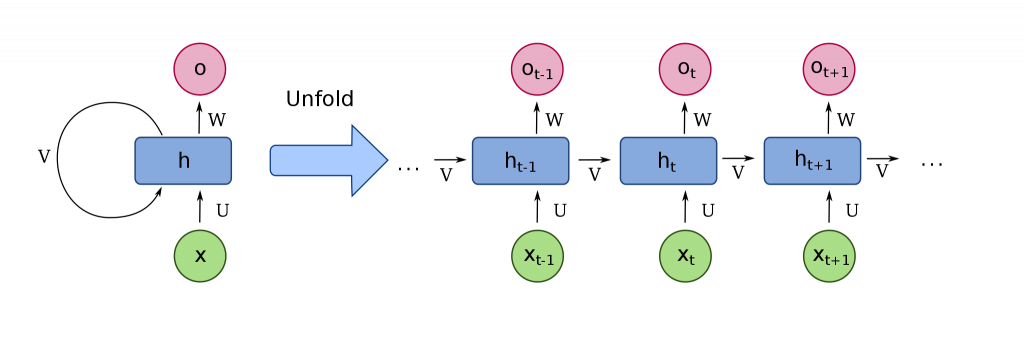
Neural networks are usually considered as a single input-output calculation. You put input information, the network runs and brings out an output. But, what if we have an input with uncertain size or length. For example, what if the input is textual, and can be constructed from 10 words or another time from 1000 words? And what if the output size is also uncertain? For example, the input text is in English and we want a French translation output which can be constructed from 10 words or another time from 1000 words?
This is where recurrent neural networks come to play. In recurrent neural network the structure of the network allows it to get one piece of input at a time and save history from previous calculations of the network. This can allow our translation example to work as follows: The network gets as an input only one word each time in English and can output only one word each time in French, keeping history of calculations for previous words. This allows for dynamically changing length of input\output while also using the context of previous input\output to understand what should be next. Language sentences usually have a grammatic and semantic structure which should be followed based on previous and future words in the sentence. Other examples of RNNs are: time series predictions, video analysis, movement tracking, robotic sensory input\output and any type of data which comes in a form of a temporal changing sequence.
What is LSTM (long short term memory)?
LSTM is a specific implementation of an RNN. LSTM keeps the state of the network, along with output and history of previous calculation. In LSTM there are 3 gates which decide how data flows:
- Input gate – Calculates how much of the new data (Xt in the diagram) and old output (Ht-1) to add to the new state (Ct)
- Forget gate – Calculates how much of the old state (Ct-1) to keep based on the new data (Xt in the diagram) and old output (Ht-1)
- Output gate – Calculates how much of the the new state (Ct) to output and also keep as history in this step of the network calculation, based on the new data (Xt in the diagram) and old output (Ht-1)
The input and forget gates are combined to calculate the new state (Ct)

What is CNN (convolutional neural network)?
When we look at a visual scene with our eyes, a similar scanning processes occurs in our mind no matter if we are looking at something large, something narrow, a specific part of the scene or the entire scene. Our brain takes a segment from our field of vision and analysis it in a repeating manner – searching for patterns, recognizing constructs, recognizing familiar shapes etc.
CNNs are a method of reconstructing that same process in a computer neural network. Instead of taking each input feature as a unique part of the entire input, the neural network is constructed to look at segments of the input in the same manner, no matter which segment and at the same time understand the construct of the entire input data and how the different features interact with each other.
A common use of CNNs is in visual input analysis (image, video, 3D model etc.). When analyzing an RGB image a CNN scans the input image using a moving window of predefined size and neural network weights. This window shrinks the information it sees each time. The entire image is scanned with this same window, creating a smaller representation of the image. Then again another window with fixed size and neural network weights is scanned over the more compact representation of the image etc. Until, we decide the the representation is compact enough and we add layers that do a specific function we choose. One of the common examples is identifying what is seen in the image, in which case a simple classification neural network structure can be added.
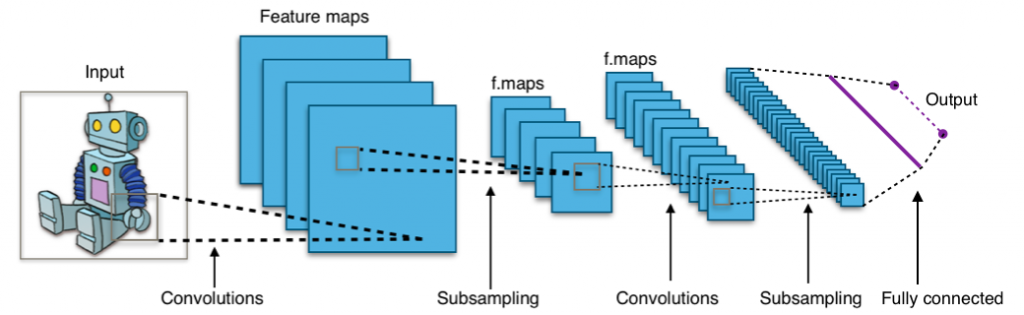
CNNs are important because they allow for a faster and more efficient method to analyze a large sized input (such as large image or video), while also allowing for shift and scale invariance – no matter in which part of the image an object appears, nor it size (as long as it is seen), it can be identified with the same CNN.
What are generative networks?
Generative neural networks are networks which are trained to generate new data, new images, new signals, many times based on a random input. Imagine generating a sentence in French (similarly to what we discussed above), but instead of having an English sentence as input, the input can be anything (even random characters in whatever language) and the output will be a clear sentence in French. By the way, the architecture this French generating network can be exactly the same as the architecture of a network which translates English to French.
What is GAN (generative adversarial network)?
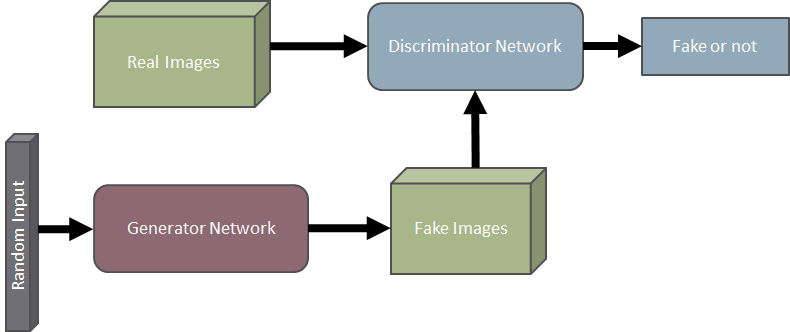
What is similar between the 3 images below? They are all images of non-existing people, generated by a GAN and taken from this website: https://thispersondoesnotexist.com/

GANs are a method of creating high quality generative neural networks. In GANs we train two neural networks – a generative network and a discriminator network. The generative network is trained to produce results which can “fool” the discriminator to think this is real data, while the discriminator is trained to recognize what data is fake and what is real. During training the discriminator is fed with real data which is labeled as such, and fake data which is labeled as such. The generator is trained with positive enforcement every time it is able to “fool” the discriminator and negative enforcement every time it is unable.Below is a general overview of a GAN which is trained to generate fake images.
2 comments
[…] GANs? Well, this same technique can be used to generate the airplanes you see […]
[…] If you’re interested in Project Management for Machine Learning , or were looking for a Deep Learning Dictionary , or want to write your own patent , Naftaliev is a wealth of […]