Back again with another AI and 3D reconstruction post for you 🙂 This time, a special article, with many cool discoveries, I might write following posts about it. This is the highest quality 3D reconstruction from 1 image research I have seen yet. An encoding-decoding type of neural network to encode the 3D structure of a shape from a 2D image and then decode this structure and reconstruct the 3D shape.
Some details
- Input image: 128X128 pixels
- Transparent image background
- Training and generation is done based on categories of similar objects
- Output voxel: Base resolution is 64X64X64 voxels. But, can produce output in any required resolution (!) without retraining the neural network
Neural Network structure:
- 2D encoder — based on ResNet18. generates and encoding vector of size 128 (z-vector) from an input image
- Decoder — simple 6 fully connected layers with 1 classification output neuron. Receives as input the z-vector and –1– 3D coordinate in space and classifies if the coordinate belongs within the mass of the object or not.
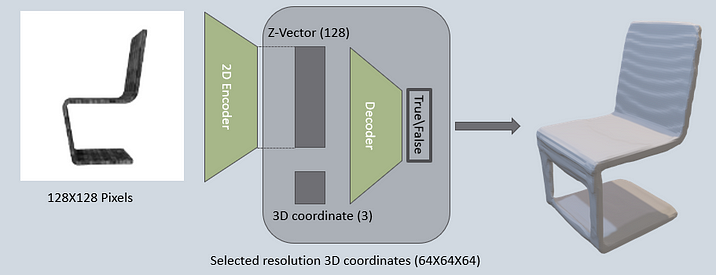
How does reconstruction occur from this network?
To reconstruct the entire structure of the object, all 3D coordinates in space are sent to the decoder (in the paper’s case there were 64X64X64 coordinates per object), along with the single z-vector from the image. The decoder classifies each coordinate and creates a representation of the 3D structure. This creates a voxel representation of the 3D object. Then, a marching cube algorithm is used to create a mesh representation.
Example of car category reconstruction

First column is the input image, second column is the AI 3D reconstruction and last column is the original 3D object of the car (or, in the technical language — ground truth). The neural network in this image case was trained over models of cars. In the paper there are results for training over chairs, airplanes and more. Notice that the input-output image and voxel resolutions are specific in this paper, but can be changed accordingly for any required implementation.
Wait! How is that last car reconstructed?
The software didn’t even see the front of the car in the image. This is where the power of DL training comes from. Since we train the network over many previous examples of cars, it knows how to extrapolate the shape of a new car it never saw before. The extrapolation is possible because the network is trained over objects from a similar category, so the network effectively reconstructs similar structures it was trained on before which match the structure it sees in the image.
Existing software for 3D reconstruction
Nowadays there are many tools available that do 3D reconstruction from images. These tools use classic photogrammetry techniques to reconstruct a 3D model from multiple images of the same object. Two examples:
This type of software can benefit from the current AI research. Reconstruction of simple planes even if they are not completely seen in the image, handling light reflections or aberrations in the image, better proportion estimations and more. All these can be improved using similar neural network solutions.
Similar research in previous post
3D scene reconstruction from single image – was for scene reconstruction, the quality of single object reconstruction didn’t look as good, but it was impressive they achieved it from a natural scene image.
ShapeNet
Similar to ImageNet for images, ShapeNet is a large dataset of annotated 3D models along with competitions and groups of people who run ML research around the subject of 3D. Most (if not all) 3D ML research uses this dataset both for training and for bench-marking, including the implicit-decoder research. There are two main Shapenet datasets, the most current is ShapeNetCore.v2:
- 55 common object categories
- About 51,300 unique 3D models
- Each 3D model’s category and alignment (position and orientation) are verified.
References
- Research: [1] Chen, Zhiqin, and Hao Zhang. “Learning implicit fields for generative shape modeling.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- Shapenet: https://www.shapenet.org/
6 comments
[…] Implicit-Decoder part 1 – 3D reconstruction […]
[…] Implicit-Decoder part 1 – 3D reconstruction […]
Long road ahead, but this looks really promising, is there any way a 3D artist can assist in such process?
This process could actually be used as part of a 3D modeling software, to help a 3D artist have a base 3D model. On this base the artist can work, adding his touches. This shortens work times because the artists gets proportions and basic structure, instead of estimating these himself manually.
[…] Peter on Implicit-Decoder part 1 – 3D reconstruction […]
please how i get source code 3D reconstruction