High Resolution Net (HRNet) is a state of the art neural network for human pose estimation – an image processing task which finds the configuration of a subject’s joints and body parts in an image. The novelty in the network is to maintain the high resolution representation of the input data and combine it in parallel with high to low resolution sub-networks, while keeping efficient computation complexity and parameters count.
In this post we will cover:
- Why HRNet?
- HRNet and Architecture
- HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
- Demo video
- Code FAQ
Why HRNet?
- Good well documented and maintained open source (link) . 2490 stars on github – of the highest rated around all human pose estimation.
- It is used as the backbone for the recent new architectures in the same research space (example in project)
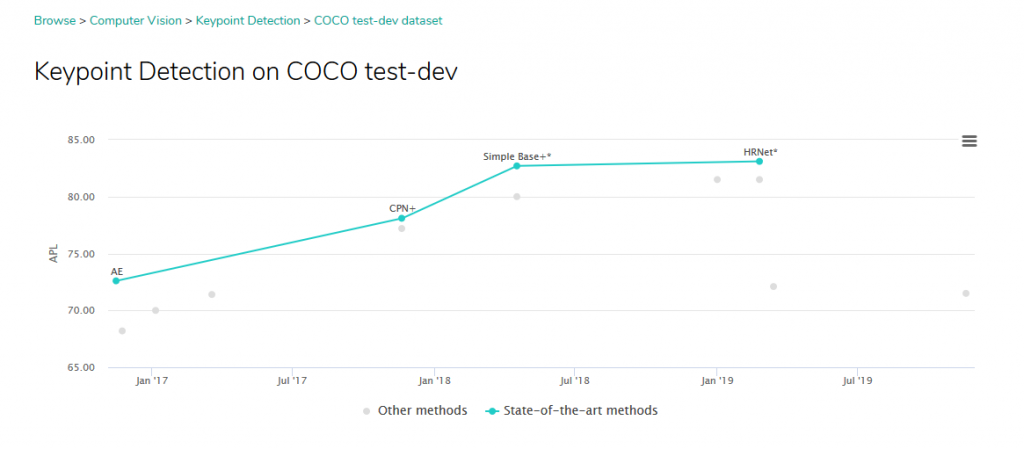
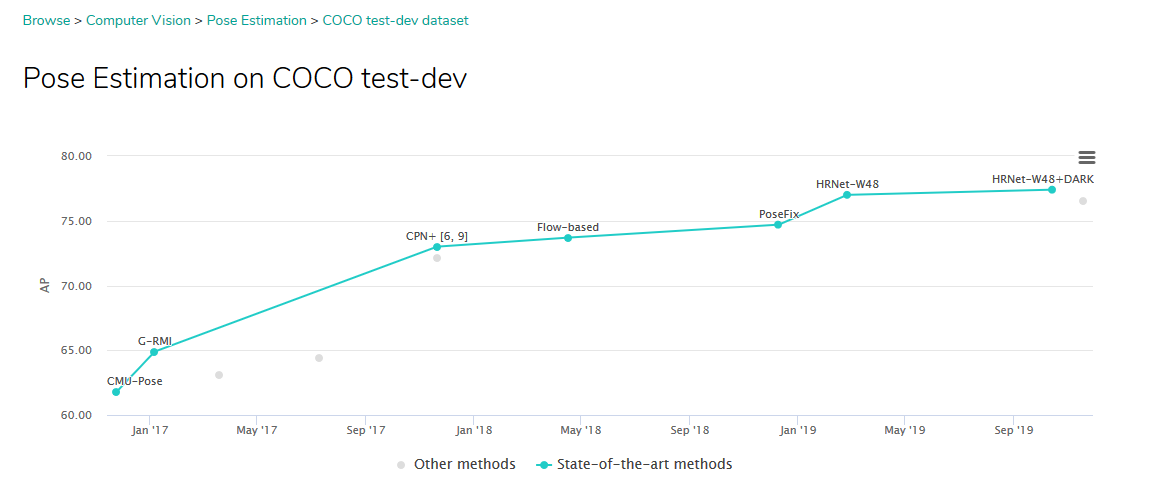
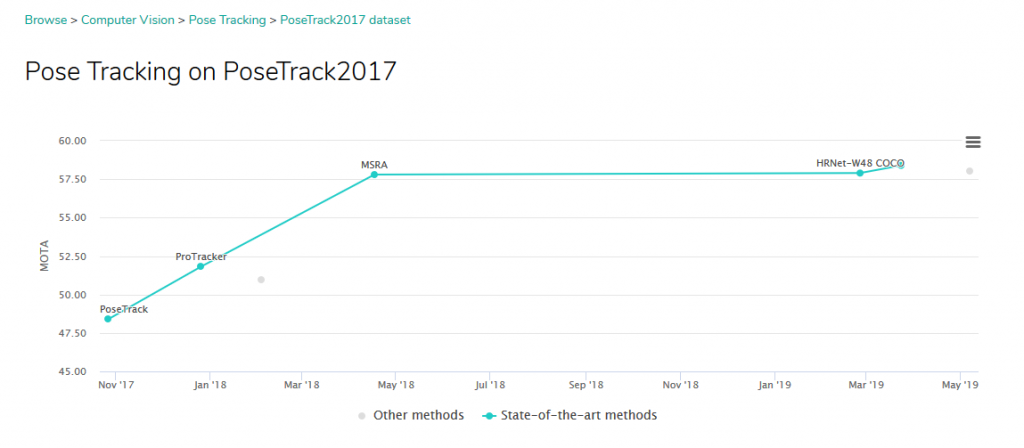
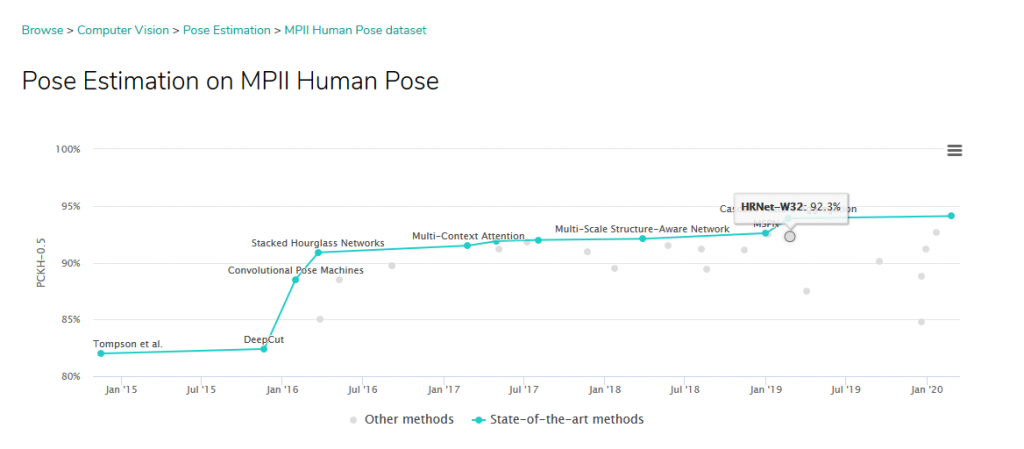
- Top competitor in many pose estimation challenges (reference):
HRNet Explained
When tackling human pose estimation, we need to be able to detect a person in the image and estimate the configuration of his joins (or keypoints). Therefore, two possible methods exist for pose estimation:
Top-down and bottom-up pose estimations
The bottom-up approach first finds the keypoints and then maps them to different people in the image, while the top-down approach first uses a mechanism to detect people in an image, put a bounding box area around each person instance and then estimate keypoint configurations within the bounding boxes.
Top-down methods rely on a separate person detection network and need to estimate keypoints individually for each person, therefore they are normally computationally intensive because they are not truly end-to-end systems. By contrast, bottom-up methods start by localizing identity-free keypoints for all the persons in an input image through predicting heatmaps of different anatomical keypoints, followed by grouping them into person instances, this effectively makes them much faster.
The top-down approach is more prevalent and currently achieves better prediction accuracy because it separates both tasks to use the specific neural networks trained for each, and because the bottom-up approach suffers from problems with predicting keypoints due to variations in scale of different people in an image (that is, until HigherHRNet appeared – below). This scale variation does not exist in top-down methods because all person instances are normalized to the same scale. While the bottom-up approach is considered to be faster because
HRNet uses the top-down method, the network is built for estimating keypoints based on person bounding boxes which are detected by another network (FasterRCNN) during inference\testing. During training, HRNet uses the annotated bounding boxes of the given dataset.
Two data sets are used for training and evaluating the network
- COCO – over 200K images and 250K person instances labeled with 17 keypoints. COCO dataset evaluation requires also evaluating the person bounding boxes, this is done using FasterRCNN network. The evaluation metric is object keypoint similarity (OKS) – a standard keypoint detection accuracy metric.
- The MPII Human Pose – around 25K images with 40K subjects. MPII evaluation is done with the annotated bounding boxes from the dataset.
Architecture
Following is the diagram of the neural network, based on the code in the git project, after which is the diagram of the network as depicted in the research paper.
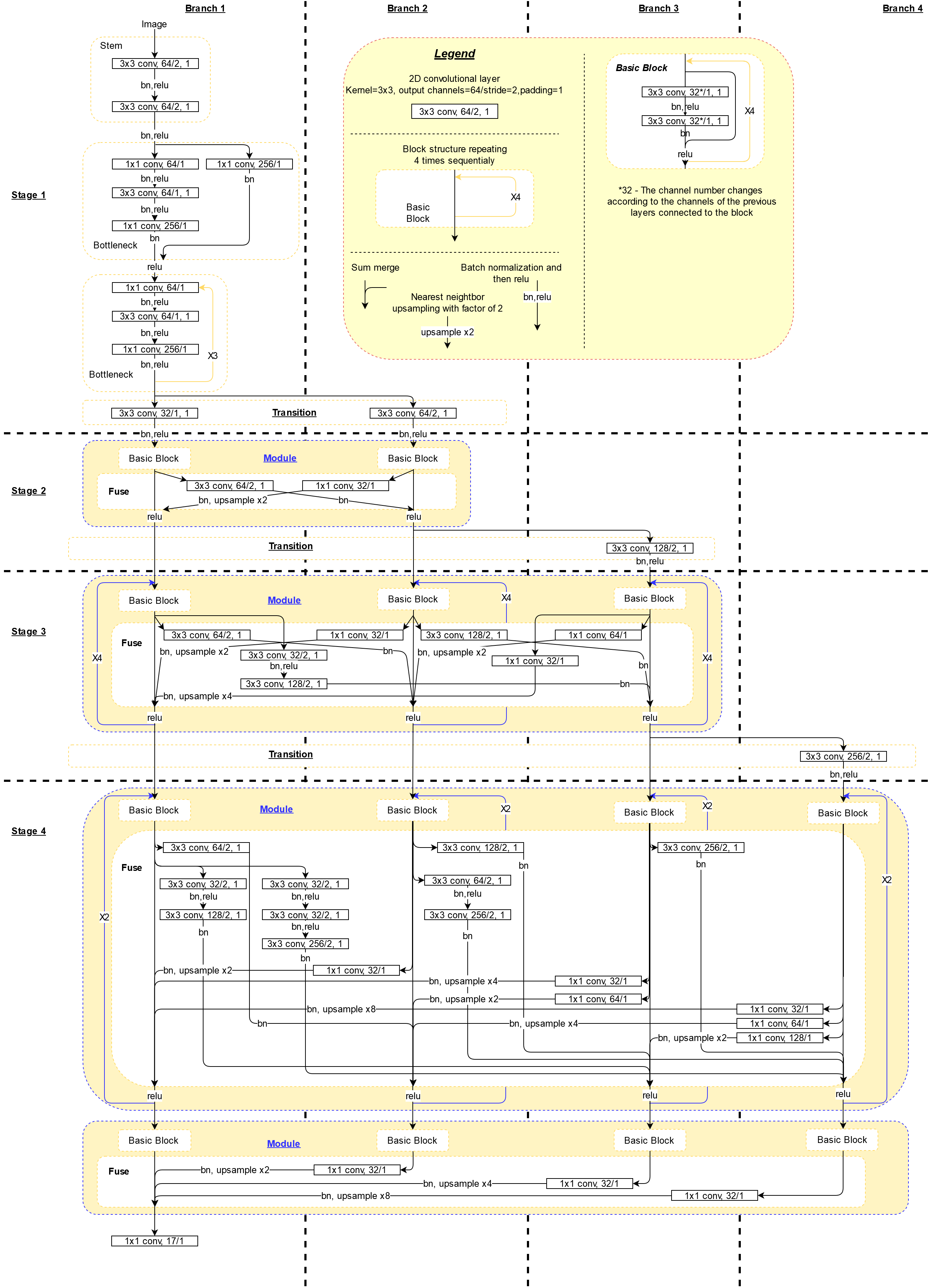
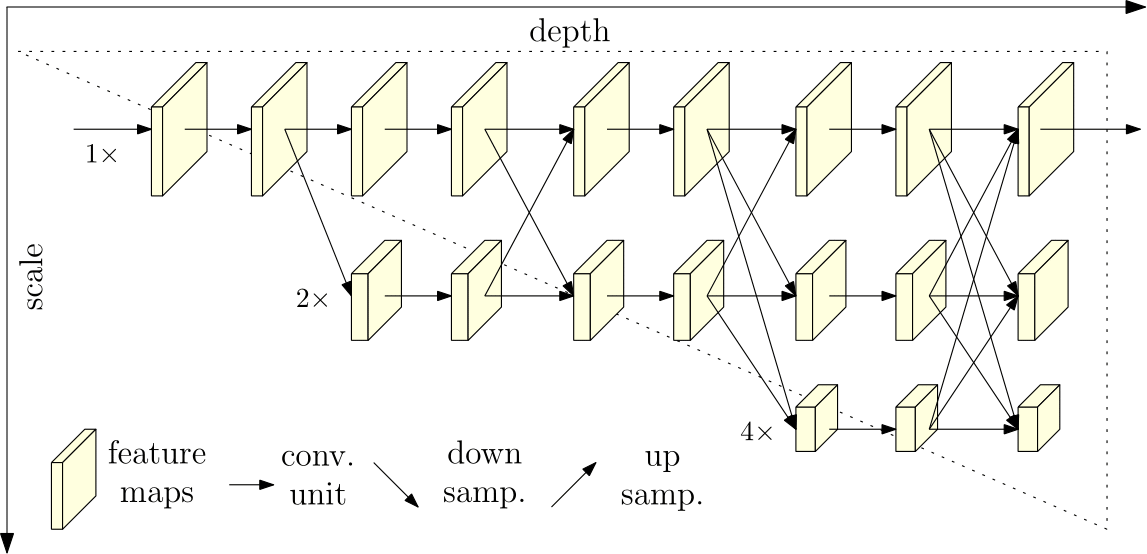
The important structure to notice is that the network calculates the high resolution sub-network (Branch 1) in parallel with lower resolution sub-networks (Branch 2-4). The sub-networks are fused through the fuse layers such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich high resolution representations.
Input image is either 256 x 192 or 384 x 288 with corresponding heatmap output size of 64 x 48 or 96 x 72. The first two convolutions diminish the input size according to the expected heatmap size. The network outputs the heatmap size and 17 channels – value per each pixel in the heatmap per each keypoint (17 keypoints).
The open source architecture depicted is for 32 channel configuration. For 48 channels change every layer starting from first transition layer and forward to 48 and it’s different multiplications by 2.
Exchange block in the paper is a module in the open source, and exchange unit is the fuse layer in the open source. In the paper diagram the transition layer looks like an independent fusion of the sub-networks, while in the code, when creating a lower resolutions (higher channel) sub-network – the transition leading to it is based on the fusion leading to the previous lowest resolution sub-network with another convolution layer. Also, in the open source the fusion of the last layer is only calculated for the high resolution branch (branch 1) and not for all the branches as seen in the paper diagram.
Down-sampling, which is the stride=2 convolutions transferring from high resolution branches to lower resolution branches at the fusion part (or exchange unit), for double and triple down-sampling only enlarges the number of channels only in the last down-sample. This is either a mistake in the code or not explicitly explained in the paper. Most probably mistake in code, since information is not mapped from the larger resolution in deeper channels for the first down-samples – Open issue in git.
If in doubt, use the diagram which is based on the open source – this is the one used when running the trained network.
Network training
- For weights initializing the authors trained the same network, with a different output layer on the ImageNet classification dataset and used the weight values as the initialization values for pose estimation training.
- Training 210 epochs of HRNet-W32 on COCO dataset takes about about 50-60 hours with 4 P100 GPUs – reference.
HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
This is the same research team’s new network for bottom-up pose tracking using HRNet as the backbone. The authors tackled the problem of scale variation in bottom-up pose estimation (stated above) and state they were able to solve it by outputting multi-resolution heatmaps and using the high resolution representation HRNet provides.
HigherHRNet outperforms all other bottom-up methods on the COCO dataset with especially large gains for medium persons. HigherHRNet also achieves state-of-the-art results on the CrowdPose dataset. The authors state that this suggests bottom-up methods are more robust to the crowded scene over top-down methods, yet there was no comparison to the regular top-down HRNet results on the same dataset.
The backbone for this network is the regular HRNet, but with an added part to the end for outputting higher resolution heatmaps:

The right part of the architecture outputs two heatmap – one for low resolution and one for high – the resolution are 128 x 128 and 256 x 256. During inference both heatmaps are mean aggregated to the higher resolution and the highest valued points are chosen for keypoint detection. The trapezoid is a deconvolution layer which outputs a 2 times higher resolution with 4 residual blocks following. Also, for each keypoint an output scalar tag is calculated, close tag values form a group of keypoints which belongs to a specific person and distant tags values indicate belonging to keypoint groups of different persons. The tags are calculated according to the “Associative Embedding” method described in this paper. The tag values are only trained and predicted for the lowest resolution heatmap because the authors found that empirically higher resolution heatmaps tag values do not learn to predict well and even do not converge.
During training, the loss function is a weighted average of the heatmap prediction loss and the tag values loss (according to the associative embedding method small distance between tags of the same group leads to lower loss and so does higher distance between tags of different groups). Each heatmap resolution loss is calculated independently according to the ground truth and they are sum-aggregated.
Checking the open source code of HigherHRNet there is no inference code available yet to create demo pose estimation videos based on the trained network.
Demo
The demo video is based on the inference script in HRNet (this is an altered script that draws sticks between joins and doesn’t open pop images while running – script link). Credit to Ross Smith’s Youtube channel.
Video characteristics
- 1920X1080 pixels, 25 frames per second, 56 seconds (1400 frames).
- Good examples of multi person, challenging scene – both homogeneous and heterogeneous background, changing background, different camera angles including zoom in and zoom out, and a dwarf in awesome poses.
Runtime information
- FasterRCNN with Resnet50 is used for person detection
- HRNet with 48 channels and 384 x 288 resolution input image used.
- Dell Laptop Core i5-7200, 32GB RAM, GeForce 940MX, Ubuntu 18.04 used. GPU reached 100% utilization during inference.
- Average time to track all bounding boxes in a frame: 1.14 sec
- Average time for all pose estimations in a frame: 0.43 sec
- Average total time for one frame parsing: 1.62 sec
- Total time for code to run inference over entire video: 2586.09 sec
Issues in the demo
When evaluating the results of an image processing algorithm, it is important to note where the algorithm did not perform well, this gives clues into its’ inherent issues:
- Shirtless people with wooden backgroud are not detected well in FasterRCNN – this might be a training data issue for the FasterRCNN network, not enough shirtless samples or not enough samples with background color similar to person color
- Big yellow trampoline detected as person (minutes 00:11) – this might show and inherent problem of FasterRCNN with homogeneous scenes.
- 17 Keypoints detected in bounding boxes even if there is no person inside the box or not all the joints are showing – HRNet is built in a way that all 17 joints must be predicted, even if they are not visual.
- It is worth noting that there is nice pose estimation even with obscuration – in the beginning of the video. Handling missing information in the image due to obscuration is tricky and HRNet is able to tackle this well.
- Also worth mentioning that the stick the dwarf holds is not estimated as one of the limbs, which is also a positive sign.
Code FAQ
- Pose tracking is done in RGB (https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/41) while person detection baseline trained network is done in BGR (https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/15)
- Working with the coco dataset API pycocotools is not compatible with python 3 https://github.com/cocodataset/cocoapi/issues/49 . HRNet mostly works, but once you started playing around with pycocotools, there might be exceptions.
- Have to use numpy 1.17: https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/177
- How to use your own dataset to train the network: https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/68
- In inference consider using model.no_grad to speed up performance and lower mem usage (I haven’t tested it)
- Third joint parameter seems to always be zero and for the joints_3d_vis object first two parameters always have the same viability flag, while the third is also zero, from coco.py ->_load_coco_keypoint_annotation_kernal(). Joints are of size 3 as a preparation for affine transform in JoinsDataset -> getitem() -> affine_transform, but the third parameter is never used (maybe it is legacy, or, it was put in place for later use for HigherHRNet). Same thing seems to happen for MPII dataset.
- During validation\test there is no use of the annotated joints (even though they are saved in the dataloader pipeline) – the accuracy results printed during the test run are not correct because of it. The entire pipeline of accuracy calculation during the test run is redundant. In the end of the run they use the coco api to calculate the right accuracy measures
- Inference is configured with 384X288 (but the Readme says to use 256X192)
Image and joints transforms
- demo/inference – box_to_center_scale() scales the image according to the boxes, but it is not clear what pixel_std=200 does. There are several open issues about it:
https://github.com/microsoft/human-pose-estimation.pytorch/issues/26
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/23
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/9
https://github.com/microsoft/human-pose-estimation.pytorch/issues/94 – “I think It is just a hyper parameter representing the default w/h of the bounding box. Just leave it alone.“ - center and scale are according to position of detected annotated bbox within the original image. Center is the center of the bbox on the original image and scale should be the size of the bbox relative to the riginal image – from coco.py->_load_coco_person_detection_results(). the bbox is constructed from x, y, w, h = box[:4] (x,y,width,height). When calculating scale, aspect ratio and normalization based on pre-configured pixel_std and 1.25 scale is done.
- inference -> get_pose_estimation_prediction returns coords on the original image (there is no rotation, just center and scale of each bounding box )
- JointsDataset->getitem->get_affine_transform gets a transformation which enlarges the scale of the original image according to how larger it is than the bbox and then centers the image in the center of the bbox.
- Then, warpAffine transfers the original image to be in the center and the scale provided, meaning we should see the area of the bbox in the output image. The output image is cropped, its’ 0,0 point correspond to the point on the original image which after transfer lands on the 0,0 coordinate, the cropping is done moving right and down from that point.
- During training the affine transform also has random rotation scaling and flipping class JointsDataset – > __getitem__()
- Objects in self.db in JointsDataset are changed by reference. self.db is populated in line 246 of class COCODataset -> _load_coco_person_detection_results().
- The transformation calculation is: x_new(of x_old),y_new(of y_old),z = T*(x_old,y_old,1)
Good place to see the example: https://docs.opencv.org/master/dd/d52/tutorial_js_geometric_transformations.html - Joints positions can be negative after transform – they are transferred with the same transformation matrix as the image,and since there is transformation towards the center and enlarging scale according to the bounding box, some joints can be outside the box.
- Center and scale annotations for MPII are not completely clear – https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/issues/51